I had a hunch I was shipping more code than everyone else. So I built the receipts.
I suspected I was carrying my team. So I built a dashboard to find out — and the architecture behind it is the part worth stealing.
- engineering
- dashboard
- mcp
- ai-sdk
- nextjs
- open-source
John Ryan Cottam 5 min read
I had a hunch I was shipping more code than everyone else. So I built the receipts.
I’m a Director of Engineering. I don’t manage anyone. I just write a lot of code.
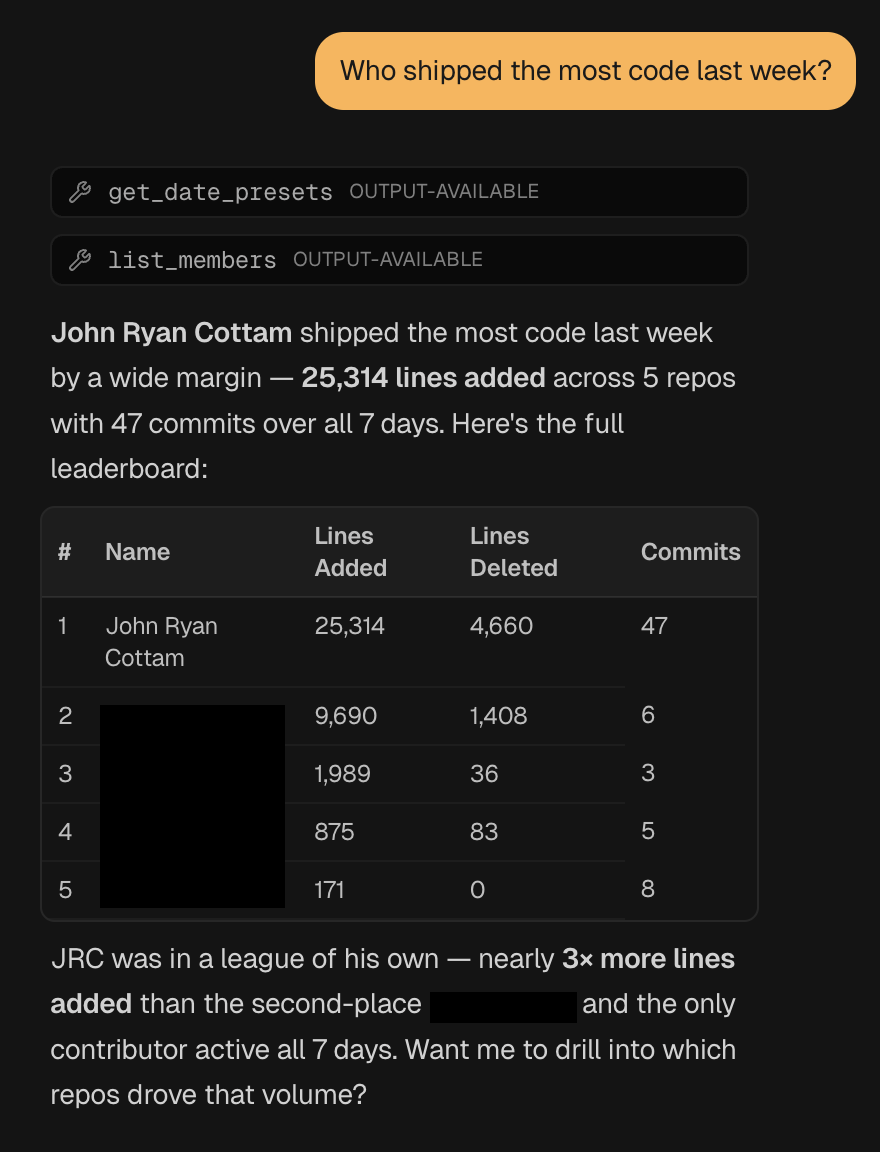
For the last few months I’ve had a quiet suspicion that I was shipping more than the engineers around me — more commits, more PRs, faster cycle times, more of the actual work that ends up in production. The kind of thing you can feel in standups but can’t prove without numbers.
So I built the numbers. It’s called Momentum. It pulls commits, PRs, lines changed, Cursor edits, and token spend out of GitHub, Azure DevOps, and Cursor’s analytics, and dumps them into one dashboard with a date picker.
The hunch was right. Not because I’m better — because I was curious whether the feeling matched reality. That’s not the interesting part of this post. The interesting part is that the dashboard exists now, every engineer on the team can see it, and the conversation about output has changed.
The thesis
Engineers should know where they stand. Not in a stack-rank, performance-review, HR-tooling way — in a “here are the receipts, here is what shipped, here is who shipped it” way. The data already exists. It’s just scattered across four tabs and nobody bothers to assemble it.
If you make it cheap to assemble — one self-hosted Next.js app, one date picker, one chat box — the whole team starts moving faster. Either because they want to show up on the leaderboard, or because they finally have a number to point at when they say they had a heavy week. Both outcomes are good.
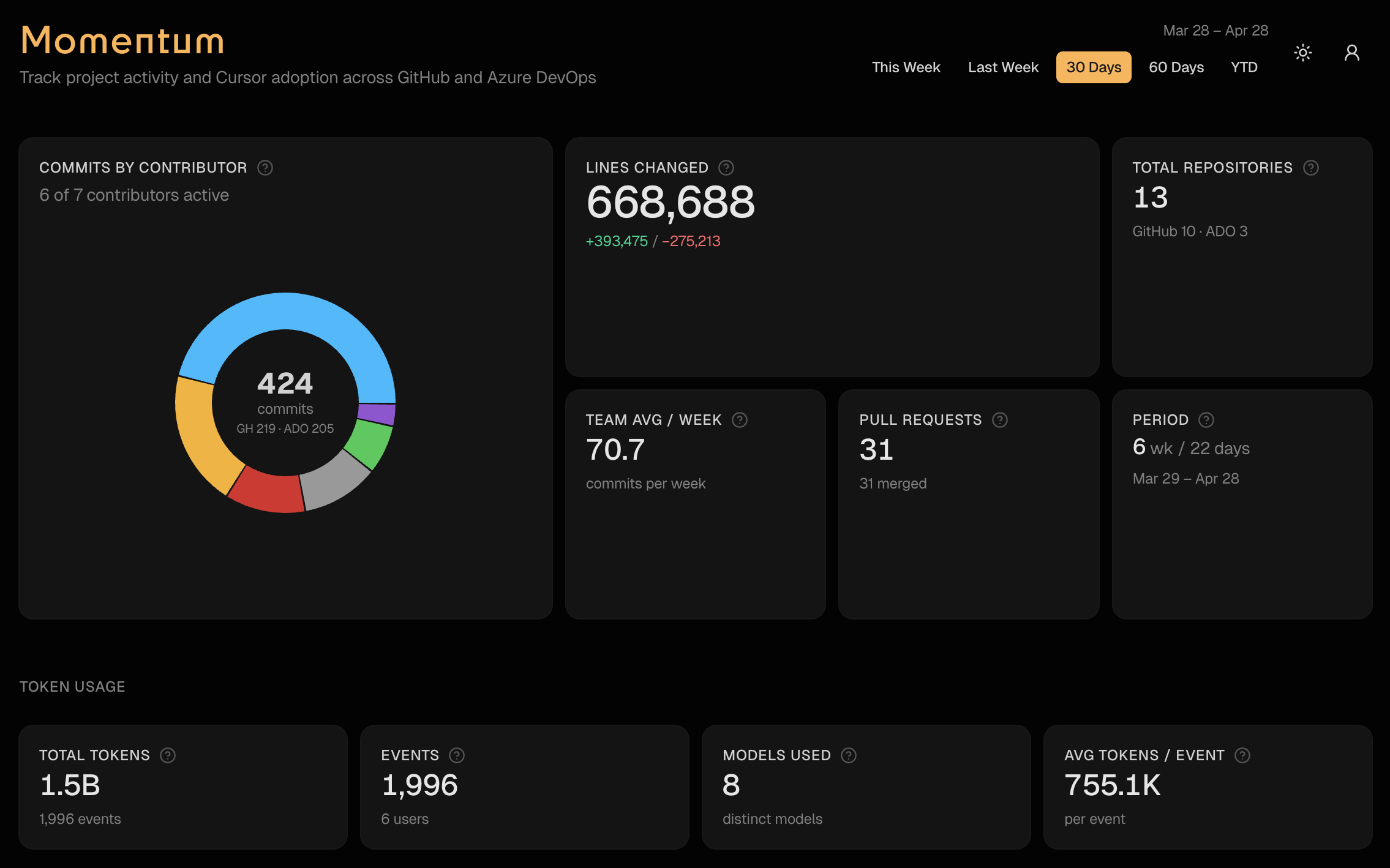
What Momentum actually does
One page, one date picker. Five presets: this week, last week, 30 days, 60 days, YTD.
- Commits, PRs, lines changed across both GitHub orgs and ADO
- Per-contributor breakdown with a click-through detail sheet
- Weekly trend charts and a cycle-time view for PRs
- Cursor adoption — agent vs Tab vs manual edits, per repo
- Token spend by user and by model
- A floating “Ask Momentum” chat that answers any of the above in plain English
- An MCP endpoint so Cursor and Claude Desktop can ask the same questions
That last bullet is the part I’m proudest of. The chat UI and the MCP server share one tool registry — so any question you can ask in the dashboard, you can also ask from your editor.
Ask it “who shipped the most code last week?” and it calls the right tools, assembles the leaderboard, and gives you a plain-English summary with the numbers to back it up.
Three primitives doing all the work
The whole thing rests on three files.
One cached corpus. A single year-to-date pull of GitHub, ADO, Cursor, and token data, cached for an hour and tagged for invalidation. The dashboard, the chat, and the MCP server all slice from the same in-memory snapshot. GitHub’s API gets hit once per hour, not once per question.
export const getRawCorpus = async (): Promise<RawCorpus> => {
"use cache"
cacheLife("hours")
cacheTag("dashboard-data")
const ytd = RANGE_PRESETS.ytd.resolve()
const [github, ado, cursorEdits, userContributor, tokenUsageRows] =
await Promise.all([
fetchGitHubData(ytd.since, ytd.until).catch(() => emptyGitHub),
fetchAdoData(ytd.since, ytd.until),
getLatestCursorEdits(),
getLatestUserContributor(),
loadTokenUsageRows(),
])
return { since: ytd.since, until: ytd.until, github, ado, cursorEdits, userContributor, tokenUsageRows }
}One tool registry. Twelve tool() definitions in one file — get_team_summary, list_members, get_pr_stats, get_token_usage, get_cursor_edits, and so on. Each one takes a Zod schema and returns small structured JSON.
export const momentumTools = {
get_team_summary: tool({
description: "Top-line metrics for a date window: commits, contributors, lines, GitHub vs ADO split.",
inputSchema: windowSchema,
execute: async ({ since, until }) => getTeamSummary(since, until),
}),
// ...11 more
}Two transports, same registry. The chat route hands momentumTools to streamText. The MCP route hands the same object to mcp-handler’s createMcpHandler. That’s the entire integration:
// /api/chat
const result = streamText({
model: CHAT_MODEL,
system: MOMENTUM_SYSTEM_PROMPT,
messages: await convertToModelMessages(messages),
tools: momentumTools,
stopWhen: stepCountIs(8),
})
// /api/mcp
const mcpHandler = createMcpHandler((server) => {
for (const [name, tool] of Object.entries(momentumTools)) {
server.registerTool(name, { description: tool.description, inputSchema: tool.inputSchema }, ...)
}
})Adding a thirteenth metric is a one-file change. Define the tool, ship it, and it shows up in both surfaces. No duplicate definitions, no drift between chat answers and what the MCP client returns.
What it would take to open source it
Momentum was built against my employer’s repos — but the org-specific bits are intentionally pinned to one file. src/lib/authors.ts is the entire human-readable config: aliases for matching duplicate identities across GitHub/ADO/Cursor CSVs, first-name display map, bot exclusions, admin emails.
export const AUTHOR_ALIASES: Record<string, string> = {
jcottam: "John Ryan Cottam",
// ...
}Three things would need to move from hard-coded to config to make this drop-in for any team:
- Org list — currently the GitHub orgs and ADO org are constants. Promote them to env vars.
- Author config — already a single file, just needs a starter template and docs.
- Cursor data shape — the Hodoscope CSV format is specific to how my employer gets analytics out of Cursor. Detect-or-disable would let teams without it run the dashboard without the AI sections.
Everything else — Supabase auth, Vercel Blob storage, AI Gateway, MCP — is pluggable infrastructure that any team running on Vercel already has.
Why I’m posting this
Two reasons.
First, the architecture is the part I think other engineers will steal. The shared-registry pattern between AI SDK chat and MCP is the cleanest seam I’ve built in a while, and most public examples wire chat tools and MCP tools as separate codepaths. They don’t have to be.
Second, if you’re an engineer who suspects you’re carrying more than your share — or who suspects the opposite and wants to know for sure — there’s no good reason that data should live behind a SaaS subscription. Self-host it, point it at your repos, find out. The conversation about engineering output gets a lot more honest when everyone is looking at the same numbers.
I’m gauging interest before I do the work to genericize and publish. If you’d run this on your team, let me know. I’m documenting the open-source process as I go.
Resources
- Momentum repo (private for now — open-sourcing TBD)
- Vercel AI SDK
mcp-handler- Build MCP Servers on Your Favorite Stack — the prior post on the MCP transport that powers this
- Model Context Protocol spec